Pivot table
diamonds %>% count(cut) %>%
mutate(prop=prop.table(n))
## # A tibble: 5 x 3
## cut n prop
## <ord> <int> <dbl>
## 1 Fair 1610 0.0298
## 2 Good 4906 0.0910
## 3 Very Good 12082 0.224
## 4 Premium 13791 0.256
## 5 Ideal 21551 0.400
df <- diamonds %>%
count(cut,color) %>%
group_by(cut) %>%
mutate(prop=prop.table(n))
df
## # A tibble: 35 x 4
## # Groups: cut [5]
## cut color n prop
## <ord> <ord> <int> <dbl>
## 1 Fair D 163 0.101
## 2 Fair E 224 0.139
## 3 Fair F 312 0.194
## 4 Fair G 314 0.195
## 5 Fair H 303 0.188
## 6 Fair I 175 0.109
## 7 Fair J 119 0.0739
## 8 Good D 662 0.135
## 9 Good E 933 0.190
## 10 Good F 909 0.185
## # … with 25 more rows
df_pivot <- diamonds %>%
count(cut,color) %>%
group_by(cut) %>%
mutate(prop=prop.table(n)) %>% select(-n) %>%
tidyr::spread(key = color,value=prop,fill=0) %>%
ungroup %>%
mutate(Total = rowSums(.[ ,-1]))
df_pivot
## # A tibble: 5 x 9
## cut D E F G H I J Total
## <ord> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Fair 0.101 0.139 0.194 0.195 0.188 0.109 0.0739 1
## 2 Good 0.135 0.190 0.185 0.178 0.143 0.106 0.0626 1
## 3 Very Good 0.125 0.199 0.179 0.190 0.151 0.0997 0.0561 1
## 4 Premium 0.116 0.169 0.169 0.212 0.171 0.104 0.0586 1
## 5 Ideal 0.132 0.181 0.178 0.227 0.145 0.0971 0.0416 1
- Pivot with multiple values
df_summ <- diamonds %>%
count(cut,color) %>%
group_by(cut) %>%
mutate(prop=prop.table(n))
df_summ_p <- data.table::dcast(data.table::setDT(df_summ),cut ~ color,value.var=c('n','prop')) %>%
mutate(n_Total = rowSums(.[,2:8]),prop_Total = rowSums(.[,9:ncol(.)])) %>%
rbind(cbind(cut='Total',as.data.frame.list(colSums(.[,-1]))))
kable(df_summ_p)
| Fair |
163 |
224 |
312 |
314 |
303 |
175 |
119 |
0.1012422 |
0.1391304 |
0.1937888 |
0.1950311 |
0.1881988 |
0.1086957 |
0.0739130 |
1610 |
1 |
| Good |
662 |
933 |
909 |
871 |
702 |
522 |
307 |
0.1349368 |
0.1901753 |
0.1852833 |
0.1775377 |
0.1430901 |
0.1064003 |
0.0625764 |
4906 |
1 |
| Very Good |
1513 |
2400 |
2164 |
2299 |
1824 |
1204 |
678 |
0.1252276 |
0.1986426 |
0.1791094 |
0.1902831 |
0.1509684 |
0.0996524 |
0.0561165 |
12082 |
1 |
| Premium |
1603 |
2337 |
2331 |
2924 |
2360 |
1428 |
808 |
0.1162352 |
0.1694583 |
0.1690233 |
0.2120223 |
0.1711261 |
0.1035458 |
0.0585889 |
13791 |
1 |
| Ideal |
2834 |
3903 |
3826 |
4884 |
3115 |
2093 |
896 |
0.1315020 |
0.1811053 |
0.1775324 |
0.2266252 |
0.1445409 |
0.0971185 |
0.0415758 |
21551 |
1 |
| Total |
6775 |
9797 |
9542 |
11292 |
8304 |
5422 |
2808 |
0.6091439 |
0.8785120 |
0.9047372 |
1.0014994 |
0.7979242 |
0.5154126 |
0.2927707 |
53940 |
5 |
- Summarise average price by cut and color
df_summ <- diamonds %>% group_by(cut,color) %>%
summarise(avg_price=mean(price), n=n())
df_summ
## # A tibble: 35 x 4
## # Groups: cut [5]
## cut color avg_price n
## <ord> <ord> <dbl> <int>
## 1 Fair D 4291. 163
## 2 Fair E 3682. 224
## 3 Fair F 3827. 312
## 4 Fair G 4239. 314
## 5 Fair H 5136. 303
## 6 Fair I 4685. 175
## 7 Fair J 4976. 119
## 8 Good D 3405. 662
## 9 Good E 3424. 933
## 10 Good F 3496. 909
## # … with 25 more rows
# Heatmap
ggplot(df_summ, aes(cut, color, fill= avg_price)) +
geom_tile() +
scale_fill_gradient(low="yellow", high="red")
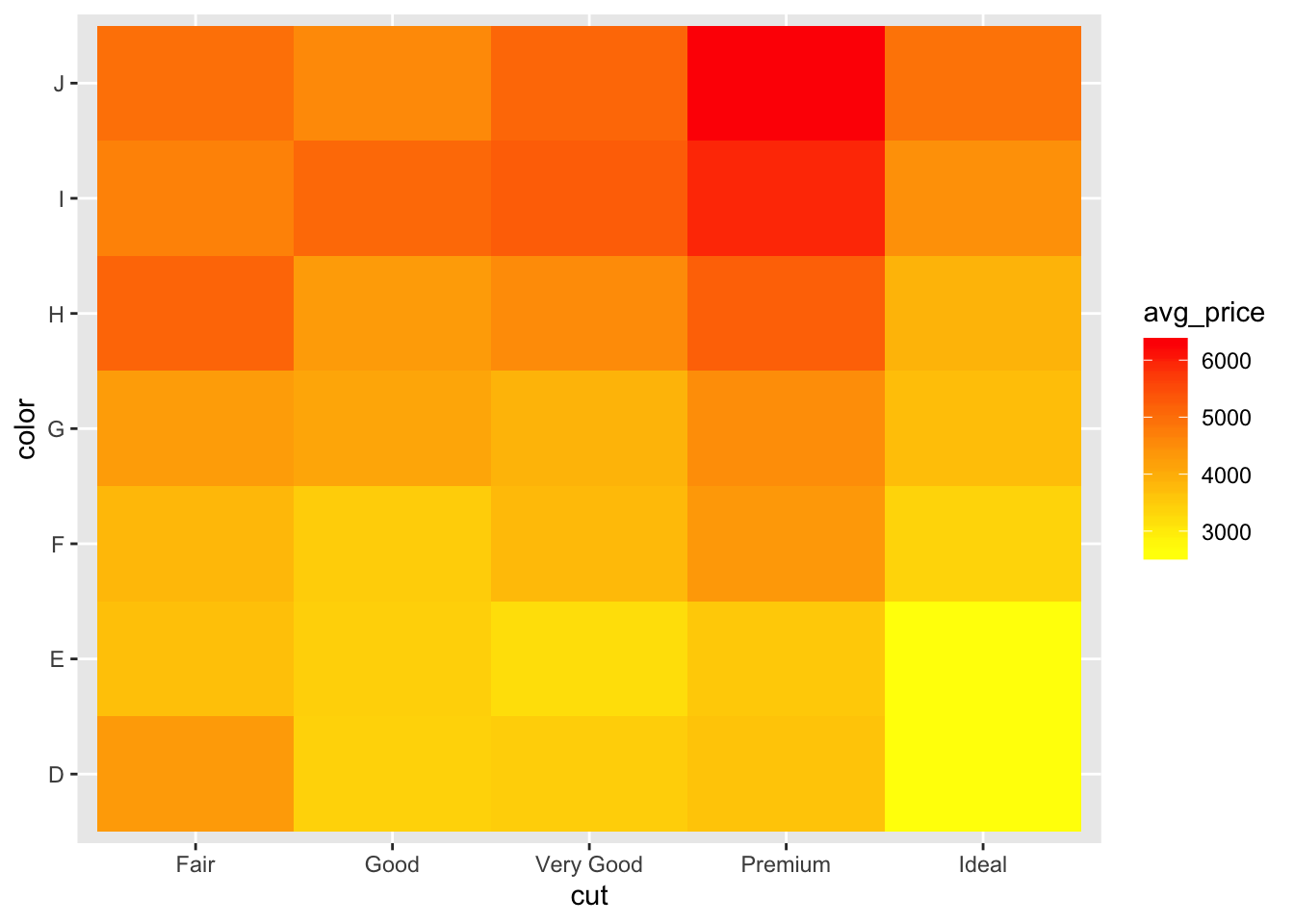
#scale_fill_distiller(palette = "RdPu")
- Pivot average price by cut and color
df_pivot_avg <- diamonds %>% group_by(cut,color) %>%
summarise(avg_price=mean(price), n=n()) %>%
select(-n) %>%
tidyr::spread(key = color,value=avg_price,fill=0) %>%
ungroup %>%
mutate(Means = rowMeans(.[ ,-1])) %>%
rbind(cbind(cut='ColMean',as.data.frame.list(colMeans(.[,-1]))))
df_pivot_avg
## # A tibble: 6 x 9
## cut D E F G H I J Means
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Fair 4291. 3682. 3827. 4239. 5136. 4685. 4976. 4405.
## 2 Good 3405. 3424. 3496. 4123. 4276. 5079. 4574. 4054.
## 3 Very Good 3470. 3215. 3779. 3873. 4535. 5256. 5104. 4176.
## 4 Premium 3631. 3539. 4325. 4501. 5217. 5946. 6295. 4779.
## 5 Ideal 2629. 2598. 3375. 3721. 3889. 4452. 4918. 3655.
## 6 ColMean 3485. 3291. 3760. 4091. 4611. 5084. 5173. 4214.
- Pivot sum count by cut and color
df_pivot_sum <- diamonds %>% group_by(cut,color) %>%
summarise(avg_price=mean(price), n=n()) %>%
select(-avg_price) %>%
tidyr::spread(key = color,value=n,fill=0) %>%
ungroup %>%
mutate(Total = rowSums(.[ ,-1])) %>%
rbind(cbind(cut='Total',as.data.frame.list(colSums(.[,-1]))))
df_pivot_sum
## # A tibble: 6 x 9
## cut D E F G H I J Total
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Fair 163 224 312 314 303 175 119 1610
## 2 Good 662 933 909 871 702 522 307 4906
## 3 Very Good 1513 2400 2164 2299 1824 1204 678 12082
## 4 Premium 1603 2337 2331 2924 2360 1428 808 13791
## 5 Ideal 2834 3903 3826 4884 3115 2093 896 21551
## 6 Total 6775 9797 9542 11292 8304 5422 2808 53940
- Pivot table with 3 group variables
df <- diamonds %>% count(cut,color,clarity)
df
## # A tibble: 276 x 4
## cut color clarity n
## <ord> <ord> <ord> <int>
## 1 Fair D I1 4
## 2 Fair D SI2 56
## 3 Fair D SI1 58
## 4 Fair D VS2 25
## 5 Fair D VS1 5
## 6 Fair D VVS2 9
## 7 Fair D VVS1 3
## 8 Fair D IF 3
## 9 Fair E I1 9
## 10 Fair E SI2 78
## # … with 266 more rows
df %>% spread(key = cut,value = n,fill = 0)
## # A tibble: 56 x 7
## color clarity Fair Good `Very Good` Premium Ideal
## <ord> <ord> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 D I1 4 8 5 12 13
## 2 D SI2 56 223 314 421 356
## 3 D SI1 58 237 494 556 738
## 4 D VS2 25 104 309 339 920
## 5 D VS1 5 43 175 131 351
## 6 D VVS2 9 25 141 94 284
## 7 D VVS1 3 13 52 40 144
## 8 D IF 3 9 23 10 28
## 9 E I1 9 23 22 30 18
## 10 E SI2 78 202 445 519 469
## # … with 46 more rows
df %>% tidyr::pivot_wider(names_from = cut,names_prefix = 'cut_'
,values_from = n
,values_fill = list(n=0))
## # A tibble: 56 x 7
## color clarity cut_Fair cut_Good `cut_Very Good` cut_Premium cut_Ideal
## <ord> <ord> <int> <int> <int> <int> <int>
## 1 D I1 4 8 5 12 13
## 2 D SI2 56 223 314 421 356
## 3 D SI1 58 237 494 556 738
## 4 D VS2 25 104 309 339 920
## 5 D VS1 5 43 175 131 351
## 6 D VVS2 9 25 141 94 284
## 7 D VVS1 3 13 52 40 144
## 8 D IF 3 9 23 10 28
## 9 E I1 9 23 22 30 18
## 10 E SI2 78 202 445 519 469
## # … with 46 more rows